Writing custom checkers for Pylint
In the world of Python we have quite decent tools for a static code analysis. There are pylint, flake8, pep8 just to name a few. Rules they enforce are based on a solid foundation - PEP8 - Style Guide for Python Code. Beside style & convention related issues, tools for SCA can detect errors like using wrong variables, typos etc. This helps a lot and leaves little room for ambiguity when it comes to coding conventions. However, there are situations when no particular convention is enforced by any standard. As a consequence, there are few possible ways of writing something down. Choosing which one is correct is up to the team that owns particular project. Of course from that moment people are responsible for enforcing new law, which of course is error prone.
Why would anybody write a custom checker?
I found myself in a similar situation few weeks ago after joining new team. These are team's rules for using import statements:
- Obey standard grouping of import statements - first standard library, then 3rd party modules and finally imports from the project
- All import statements go before from ... import
- imports in each group have to be sorted alphabetically
- stuff imported inside from ... import has also be sorted
Correct example:
import os
from os import path
from django.conf import settings
from django.db.models import (
CharField,
Field,
)
import project.views
from project.models import User
Incorrect example:
from os import path # this should be after 'import os'
import os
from django.conf import settings
from django.db.models import (
Field, # this should be after 'CharField'
CharField,
)
These rules are not something extraordinary, yet it takes some time to get used to them. Even after few months in the project one can make a mistake and misplace imports. I made plenty such errors in the beginning of the work in the project. It must have been irritating for other team members to point out these over and over. So to spare my teammates some nerves and time, I come up with an idea to write a custom checker for pylint.
Pylint is a pluggable piece of software that can be easily extended with such custom rules, yet they have to be programmed. There are two approaches when writing custom checker - treat code as an Abstract Syntax Tree or raw string. For this particular application AST analysis was much more handy, so I went this way.
What are ASTs, actually?
Abstract syntax trees are a way of representing code in an easily parsable way. To grasp a general idea, consider following example:
import astroid
source_code = '''import time
def ten_seconds_ago():
now = time.time()
return now - 10
'''
ast = astroid.parse(source_code)
print(ast)
# Module(name='',
# doc=None,
# file='<?>',
# path='<?>',
# package=False,
# pure_python=True,
# future_imports=set(),
# body=[ <Import l.1 at 0x1049ddf98>,
# <FunctionDef.ten_seconds_ago l.3 at 0x1049c0048>])
print(ast.body)
# [<Import l.1 at 0x1049ddf98>, <FunctionDef.ten_seconds_ago l.3 at 0x1049c0048>]
print(ast.body[1])
# FunctionDef.ten_seconds_ago(name='ten_seconds_ago',
# doc=None,
# decorators=None,
# args=<Arguments l.3 at 0x1049c00b8>,
# returns=None,
# body=[ <Assign l.4 at 0x1049bff28>,
# <Return l.5 at 0x1049e3320>])AST is a structure that contains our code. We see that root element is a Module. In its body it has Import and FunctionDef. If we look further, into FunctionDef element we discover it also has body with Assign and Return.
I use astroid library - it's a boosted variation of standard library's ast module. Pylint uses astroid extensively.
That's the basic idea - we get nested structure of objects which represent single statements in our code. Such exemplary piece of code:
import time
def ten_seconds_ago():
now = time.time()
return now - 10is turned into this:
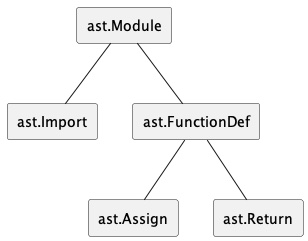
Of course AST stores additional things such as node position, so it is an exact code representation.
Many pylint's checkers works by visiting nodes in a given AST. One has two callbacks to implement per each node type, visit_<nodename> and leave_<nodename>. First one is invoked when tree traversal reaches particular node and second when we come back as there is no more left to traverse. Depth First Search algorithm is used for traversing the tree. It makes sense, because we are able to gather all statements in a function and inside leave_functiondef do some stuff, like check the number of assignments or something.
Let's start with an implementation of first, simpler rule - all names imported in from .. import should be sorted alphabetically. Prepare example file which violates that rule:
"""
`getdoc` should land before `getmodule`
"""
from inspect import (
getmodule,
getdoc,
)
print(getmodule(getdoc))
print(getdoc(getmodule))
Running pylint shows no problems:
~/P/p/linting> pylint first_rule.py -------------------------------------------------------------------- Your code has been rated at 10.00/10 (previous run: 10.00/10, +0.00)
First, we need a checker boilerplate code:
import astroid
from pylint.interfaces import IAstroidChecker
from pylint.checkers import BaseChecker
class AlphabeticallySortedImports(BaseChecker):
__implements__ = IAstroidChecker
name = 'alphabetically-sorted-imports-checker'
UNSORTED_IMPORT_FROM = 'unsorted-import-from'
DIR_HIGHER = 'higher'
DIR_LOWER = 'lower'
# here we define our messages
msgs = {
'C5001': ('"%s" in "%s" is in the wrong position. Move it %s.',
UNSORTED_IMPORT_FROM,
'Refer to project rules on wiki'),
}
options = ()
priority = -1
def visit_importfrom(self, node):
pass # to be implemented
def register(linter):
"""required method to auto register this checker"""
linter.register_checker(AlphabeticallySortedImports(linter))
Actual implementation is pretty easy:
def visit_importfrom(self, node):
# node is an astroid.node_classes.ImportFrom instance
# it has names property with 2-element tuples that contain
# object name and it's alias (or None, if not aliased)
names = [name for name, _alias in node.names]
# we sort all names to get desired structure
sorted_names = sorted(names)
for actual_index, name in enumerate(names):
correct_index = sorted_names.index(name)
# if our object is not placed in the same order as in
# sorted_names, then we report this fact as a violation
if correct_index != actual_index:
direction = self.DIR_LOWER if correct_index > actual_index else self.DIR_HIGHER
args = name, node.as_string(), direction
# this function causes pylint to emit warning
self.add_message(
self.UNSORTED_IMPORT_FROM, node=node, args=args
)Now we run pylint with our custom checker and it complains as we expected:
~/P/p/linting> pylint first_rule.py --load-plugins=alphabetically_sorted_imports ************* Module first_rule C: 5, 0: "getmodule" in "from inspect import getmodule, getdoc" is in the wrong position. Move it lower. (unsorted-import-from) C: 5, 0: "getdoc" in "from inspect import getmodule, getdoc" is in the wrong position. Move it higher. (unsorted-import-from) ------------------------------------------------------------------- Your code has been rated at 3.33/10 (previous run: 10.00/10, -6.67)
After fixing positions
"""
Everything's fine now
"""
from inspect import (
getdoc,
getmodule,
)
print(getmodule(getdoc))
print(getdoc(getmodule))
Pylint checks pass:
~/P/p/linting [16]> pylint first_rule.py --load-plugins=alphabetically_sorted_imports ------------------------------------------------------------------- Your code has been rated at 10.00/10 (previous run: 3.33/10, +6.67)
Second rule is much more tricky to get it implemented right. By looking into original pylint imports checker module's code I discovered it can be reused, because it already gathers all Import and ImportFrom statements together and can even organize them into groups of entities that come from standard library, 3rd party or are local imports.
First, code that violates this rule:
""" `inspect` should land before `from inspect import ...` `astroid` should be imported before from `pylint.checkers.imports import ImportsChecker` """ from inspect import getdoc import inspect from pylint.checkers.imports import ImportsChecker import astroid print(getdoc(inspect)) print(getdoc(astroid)) print(getdoc(ImportsChecker))
Secondly, implementation. All interesting places are commented:
import astroid
from astroid.node_classes import ImportFrom
from pylint.interfaces import IAstroidChecker
from pylint.checkers import BaseChecker
from pylint.checkers.imports import ImportsChecker
class AlphabeticOrderImportChecker(BaseChecker):
"""
Checking imports order according to `Project rules`
written down on Confluence.
"""
__implements__ = IAstroidChecker
name = 'alphabetic-import-order-checker'
UNSORTED_IMPORT = 'unsorted-import'
UNSORTED_IMPORT_FROM = 'unsorted-import-from'
DIR_HIGHER = 'higher'
DIR_LOWER = 'lower'
msgs = {
'C5000': ('Import "%s" is in the wrong position. Move it %s.',
UNSORTED_IMPORT,
'Refer to project rules on wiki'),
'C5001': ('"%s" in "%s" is in the wrong position. Move it %s.',
UNSORTED_IMPORT_FROM,
'Refer to project rules on wiki'),
}
options = ()
priority = -1
def __init__(self, linter):
super().__init__(linter)
# I use original pylint's ImportsChecker as a property
self.imports_checker = ImportsChecker()
def visit_importfrom(self, node):
names = [name for name, _alias in node.names]
sorted_names = sorted(names)
for actual_index, name in enumerate(names):
correct_index = sorted_names.index(name)
if correct_index != actual_index:
direction = self.DIR_LOWER if correct_index > actual_index else self.DIR_HIGHER
args = name, node.as_string(), direction
self.add_message(
self.UNSORTED_IMPORT_FROM, node=node, args=args
)
# new code in this method - copy & paste from ImportsChecker
# so it can classify import later
basename = node.modname
imported_module = self.imports_checker._get_imported_module(node, basename)
if isinstance(node.scope(), astroid.Module):
self.imports_checker._record_import(node, imported_module)
def visit_import(self, node):
"""
copy & paste from ImportsChecker, so it can classify import later
"""
modnode = node.root()
names = [name for name, _ in node.names]
for name in names:
imported_module = self.imports_checker._get_imported_module(node, name)
if isinstance(node.scope(), astroid.Module):
self.imports_checker._record_import(node, imported_module)
def leave_module(self, node):
"""
Actual checks are implemented here
"""
std_imports, ext_imports, loc_imports = self.imports_checker._check_imports_order(node)
for group in std_imports, ext_imports, loc_imports:
self._check_imports_order_in_group(group)
self.imports_checker._imports_stack = []
self.imports_checker._first_non_import_node = None
def _check_imports_order_in_group(self, group):
"""
Per each group of imports we check whether they are
on correct position within its group.
"""
def sort_algo(item):
"""
import statements are always before import ... from.
Then alphabetic order should be applied
"""
import_node, import_name = item
is_import_from = 1 if isinstance(import_node, ImportFrom) else 0
# This is a trick - sorting by multiple keys using tuples
return (is_import_from, import_name)
sorted_imports_group = sorted(group, key=sort_algo)
for actual_index, (import_node, import_name) in enumerate(group):
correct_index = sorted_imports_group.index((import_node, import_name))
if correct_index != actual_index:
direction = self.DIR_LOWER if correct_index > actual_index else self.DIR_HIGHER
args = import_node.as_string(), direction
self.add_message(
self.UNSORTED_IMPORT, node=import_node, args=args
)
def register(linter):
"""required method to auto register this checker"""
linter.register_checker(AlphabeticOrderImportChecker(linter))
Our checks obviously fails:
~/P/p/linting [16]> pylint second_rule.py --load-plugins=my_checker ************* Module second_rule C: 6, 0: Import "from inspect import getdoc" is in the wrong position. Move it lower. (unsorted-import) C: 7, 0: Import "import inspect" is in the wrong position. Move it higher. (unsorted-import) C: 9, 0: Import "from pylint.checkers.imports import ImportsChecker" is in the wrong position. Move it lower. (unsorted-import) C: 10, 0: Import "import astroid" is in the wrong position. Move it higher. (unsorted-import) ------------------------------------------------------------------ Your code has been rated at 4.29/10 (previous run: 4.29/10, +0.00)
Fixing code
""" `inspect` should land before `from inspect import ...` `astroid` should be imported before from `pylint.checkers.imports import ImportsChecker` """ import inspect from inspect import getdoc import astroid from pylint.checkers.imports import ImportsChecker print(getdoc(inspect)) print(getdoc(astroid)) print(getdoc(ImportsChecker))
makes Pylint happy again:
~/P/p/linting [16]> pylint second_rule.py --load-plugins=my_checker ------------------------------------------------------------------- Your code has been rated at 10.00/10 (previous run: 4.29/10, +5.71)
Conclusion
No software developer should spent time on manually checking things that SCA should take care of. We have much better things to do. ;) Let me know in the comments if you have ever come across any problem that custom checks of Pylint could solve.
All code presented in this post is GPL-2 licensed (just like Pylint), so enjoy. Don't forget to read sources of Pylint - the most fundamental source of information in this blog post.